A distância de Cook é uma medida estatística essencial em modelos de regressão. Em síntese, ela indica o quanto uma única observação influencia as estimativas dos coeficientes do modelo.
Em outras palavras, se um único caso tiver um impacto desproporcional sobre o resultado da regressão, a distância de Cook irá sinalizar isso. Portanto, essa métrica ajuda a identificar pontos que podem distorcer as conclusões da análise.
Além disso, seu uso é especialmente importante quando queremos garantir que nossas estimativas sejam robustas e representativas do conjunto de dados como um todo.

Exemplo prático de distância de Cook na regressão
A fim de ilustrar o que é a distância de Cook, usaremos um exemplo. Imagine que queremos prever o bem-estar no trabalho com base na distância (em km) entre casa e trabalho.
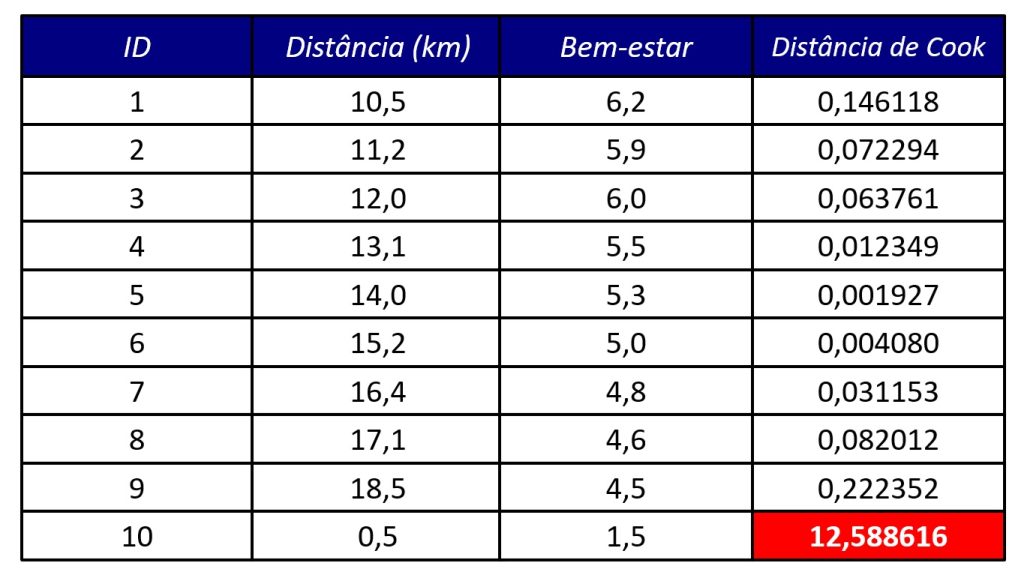
Em nosso banco de dados, todas as pessoas moram a pelo menos 10 km do trabalho, exceto uma: ela mora a 500 m da empresa e apresenta um baixo nível de bem-estar (Figura 1, ID = 10).
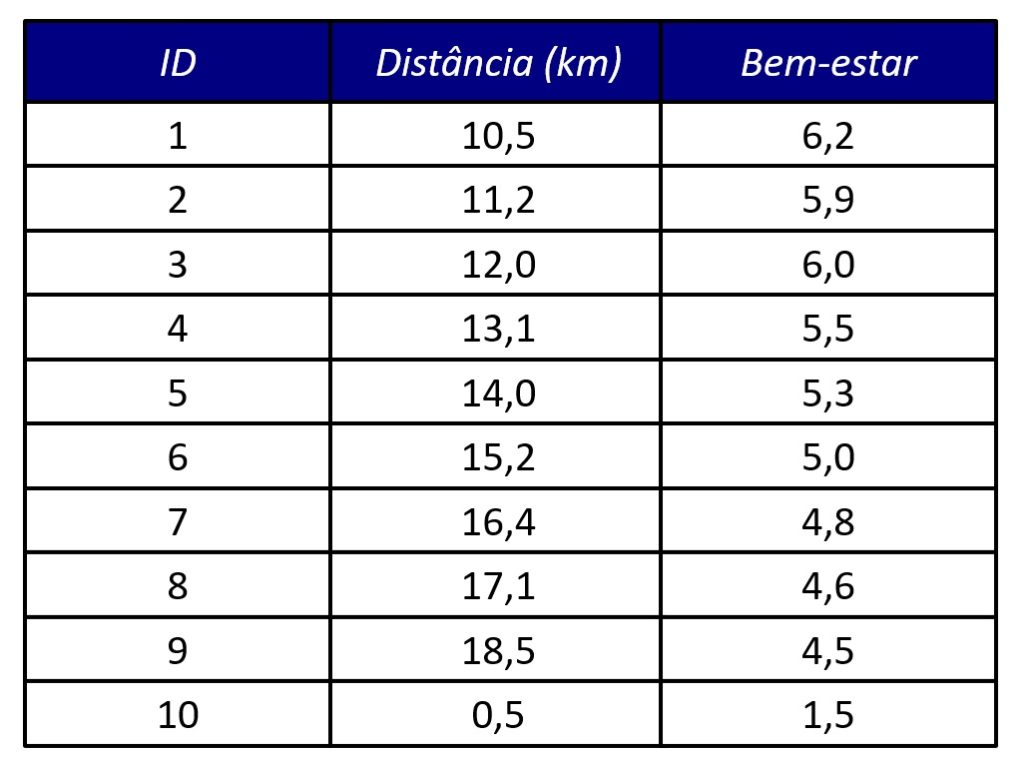
Nesse cenário, essa observação pode influenciar substancialmente o modelo de regressão. Desse modo, as estimativas gerais podem se tornar menos confiáveis.
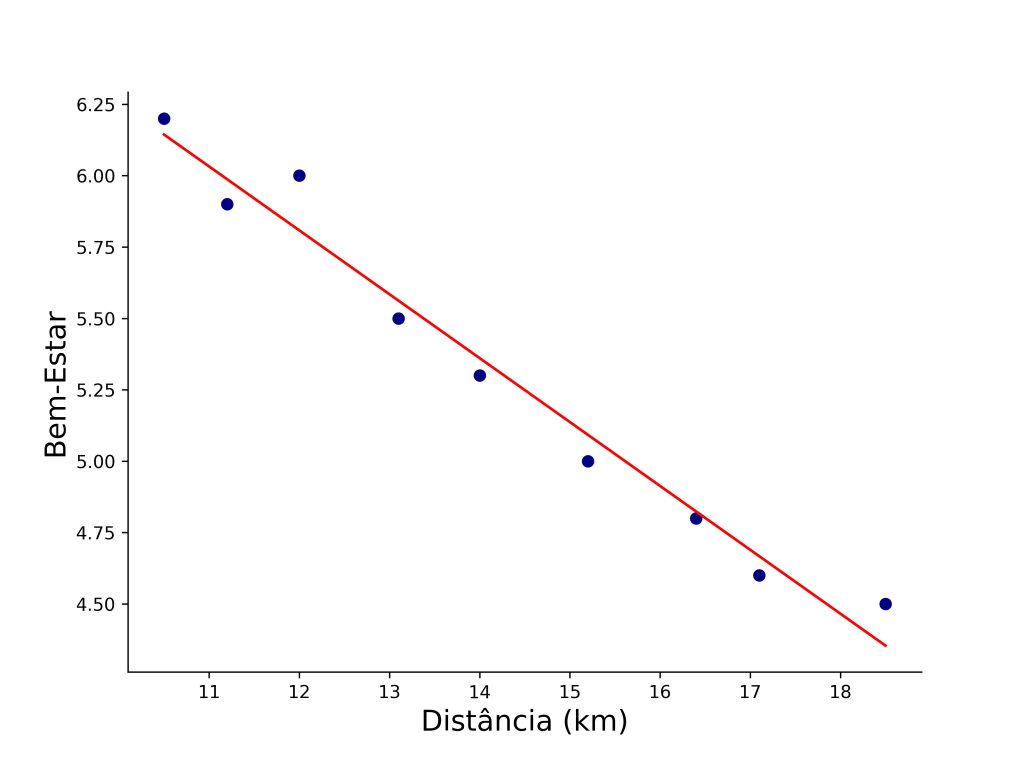
Em nosso exemplo, obtivemos um modelo de regressão linear simples não significativo, F(1, 8) = 3,36, p = 0,11, R² = 0,30, R² ajustado = 0,21, com os coeficientes b0 = 3,08, t = 2,85, p = 0,02, e b1 = 0,14, t = 1,83, p = 0,10. Note, contudo, que, embora o slope seja positivo (b1 = 0,14), esse resultado parece ser guiado pelo ID = 10, que é um valor influente no banco de dados (Figura 2).
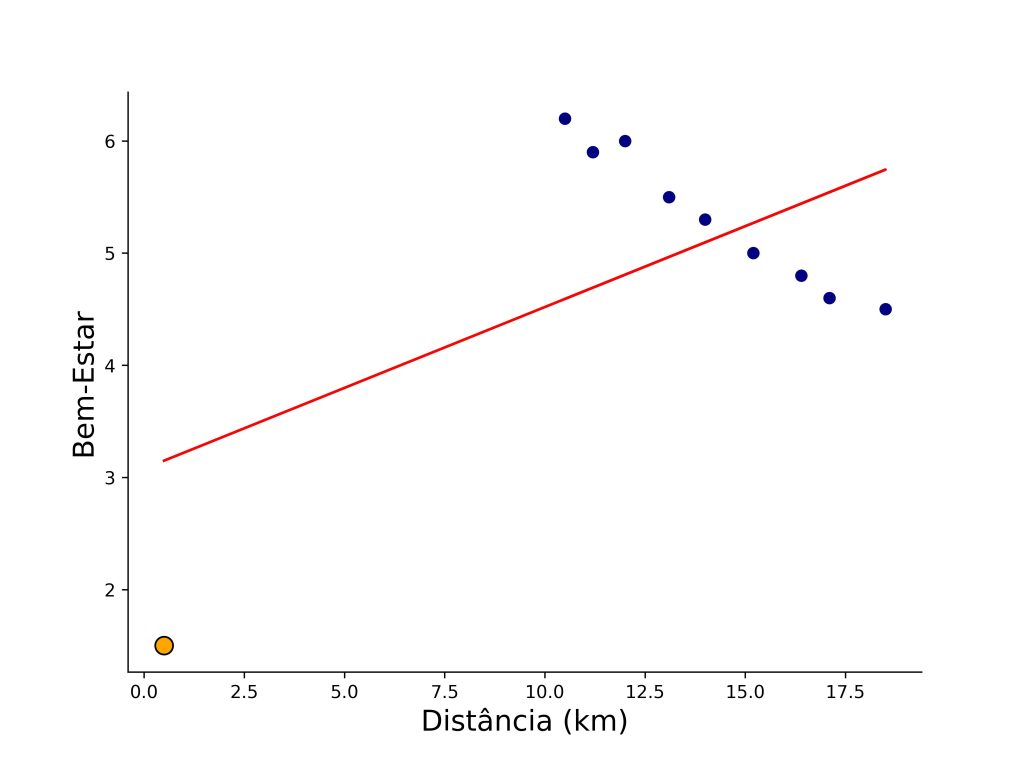
Aqui entra a utilidade da distância de Cook, uma vez que ele calcula a diferença entre os resultados do modelo com e sem essa observação. Assim, conseguimos avaliar, quantitativamente, o quanto esse caso específico distorce a análise. Quando realizamos os cálculos das distâncias de Cook, o valor do ID = 10 se destaca, com um valor de D = 12,59 (Figura 3).
Quando a distância de Cook indica alerta?
A regra prática mais comum estabelece que, se a distância de Cook for maior que 1, o ponto é potencialmente influente e merece atenção. Por exemplo, a Figura 4 ilustra como a reta de regressão do modelo anterior muda quando removemos o ID = 10 dos dados. Em outras palavras, ID = 10 é altamente influente.
Agora, mesmo com um caso a menos, o modelo de regressão linear simples foi estatisticamente significativo, F(1, 7) = 239,43, p < 0,001, R² = 0,99, R² ajustado = 0,97, com os coeficientes b0 = 8,49, t = 40,62, p < 0,001, e b1 = –0,22, t = –15,47, p < 0,001.
Entretanto, antes de excluir observações com alto valor de distância de Cook, é fundamental analisar suas causas. Por exemplo, erros de digitação ou registros claramente incorretos justificam a remoção.
Por outro lado, se o dado estiver correto, ele pode representar um caso legítimo — e até relevante — dentro do fenômeno estudado. Conforme destacaram Bollen e Jackman (1985), essas observações atípicas podem, em certos contextos, ser as mais informativas.
Conclusão
Como você viu, a distância de Cook é uma ferramenta poderosa para identificar observações influentes. Ainda assim, seu uso exige cuidado e interpretação criteriosa.
Quer aprofundar seus conhecimentos sobre regressão, base fundamental para entender esse conceito? Então explore nossos artigos e domine a técnica por completo.
Se você precisa aprender análise de dados, então faça parte da Psicometria Online Academy, a maior formação de pesquisadores quantitativos da América Latina. Conheça toda nossa estrutura aqui e nunca mais passe trabalho sozinho(a).
Referências
Bollen, K. A., & Jackman, R. W. (1985). Regression diagnostics: An expository treatment of outliers and influential cases. Sociological Methods & Research, 13(4), 510–542. https://doi.org/10.1177/0049124185013004004
Field, A. (2017). Discovering statistics using IBM SPSS Statistics (5th ed.). Sage.
Como citar este post
Damásio, B. (2025, 16 de junho). O que é a distância de Cook? Blog Psicometria Online. https://www.blog.psicometriaonline.com.br/o-que-e-a-distancia-de-cook/