Neste post, falaremos sobre dados faltantes. Primeiramente, explicaremos o que são dados faltantes, por que eles acontecem em pesquisas científicas e por que devemos nos importar com eles. Em seguida, descreveremos os principais tipos de dados faltantes, com exemplos práticos. Nós então discutiremos as consequências do tratamento inadequado desses dados. Por fim, apresentaremos estratégias modernas para lidar com dados faltantes, como imputação múltipla e maximização da expectativa.
Entendendo o que são dados faltantes
Em termos simples, dados faltantes (também chamados de dados ou valores ausentes, ou missing data) consistem em valores de uma variável que não são registrados em uma pesquisa (Figura 1). Em outras palavras, temos dados faltantes quando as informações que esperávamos obter de um participante simplesmente não estão disponíveis.
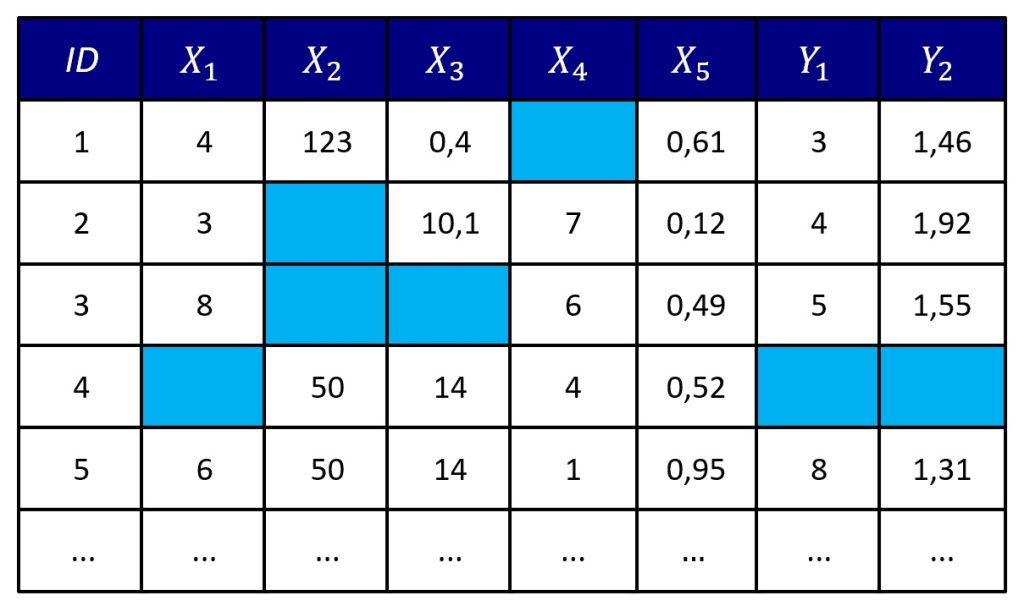
Esse fenômeno é comum em estudos nas ciências humanas e sociais, principalmente quando os participantes se recusam a responder certas perguntas ou abandonam a pesquisa antes do fim.
Por exemplo, imagine um estudo sobre saúde mental no qual alguns participantes preferem não responder questões sobre uso de substâncias. Consideramos tais omissões como respostas ausentes — e precisamos tratá-las cuidadosamente, a fim de não comprometermos as inferências de nossa pesquisa.
Por que surgem dados faltantes?
Existem muitas razões para o surgimento de dados faltantes. Em seguida, listamos algumas das mais comuns:
- Recusa do participante: questões sensíveis, como renda ou comportamento sexual, podem gerar desconforto e levar à não resposta.
- Distração ou cansaço: o participante pula uma questão sem perceber ou abandona a pesquisa por fadiga.
- Problemas técnicos: falhas no sistema de coleta, como um erro no formulário on-line.
- Desistência do estudo: participantes que não retornam em etapas subsequentes de pesquisas longitudinais.
Esses cenários mostram que os dados faltantes podem ter causas variadas — e compreender essas causas é o primeiro passo para tratá-los adequadamente.

Por que se importar com dados faltantes?
Devemos nos importar com dados faltantes porque eles podem revelar aspectos cruciais de um fenômeno. Às vezes, o que não foi observado conta mais do que o que está presente. Um exemplo marcante da Segunda Guerra Mundial ilustra bem essa ideia.
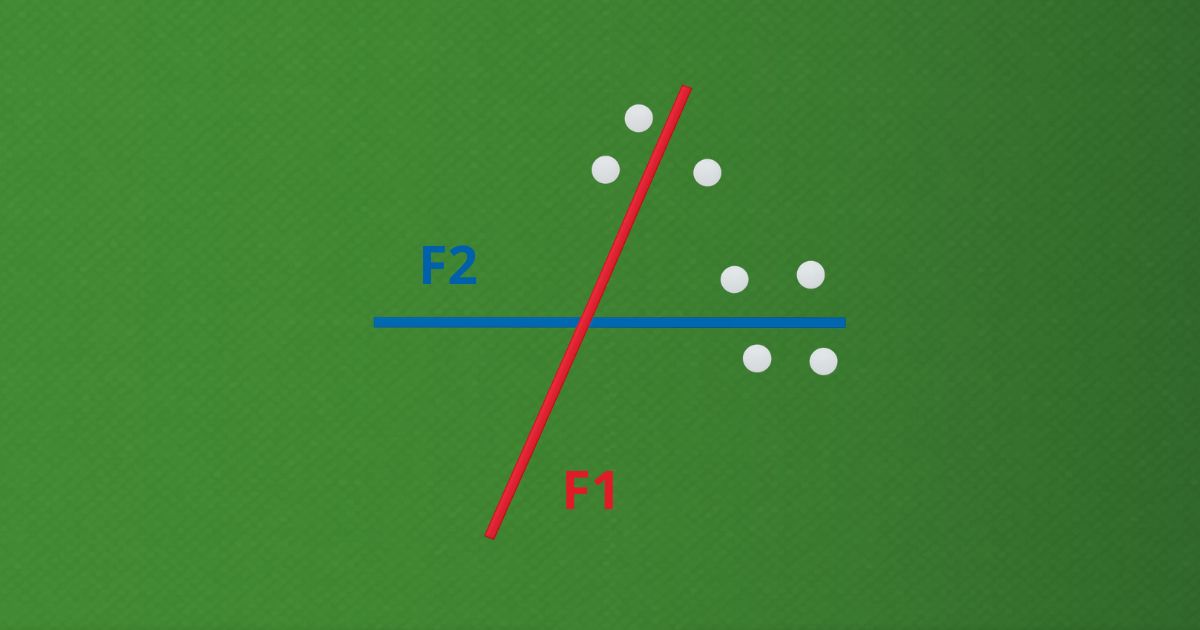
Na época, os militares dos EUA queriam reforçar a blindagem de seus aviões. Analisaram os pontos danificados nos que retornavam das missões — fuselagem e asas eram as áreas mais atingidas. Pareciam, portanto, as que mais precisavam de proteção. Mas o matemático Abraham Wald (Figura 2) pensou diferente.

Wald percebeu que os valores ausentes eram os próprios aviões que não retornavam. Ou seja, os danos críticos — especialmente nos motores — simplesmente não apareciam na amostra, pois os aviões atingidos nessas partes caíam antes de voltar. Assim, ele concluiu que os militares deveriam reforçar a blindagem onde não havia marcas de tiro visíveis nos aviões que voltavam (Figura 3).

Essa inversão de lógica — olhar para o que está ausente, e não apenas para o que está presente — nos mostra por que compreender os dados faltantes é tão essencial. Ignorá-los pode nos levar a tomar decisões erradas, como proteger o que já sobrevive bem, enquanto deixamos vulneráveis os pontos realmente frágeis.
Tipos de dados faltantes
Donald Rubin, em 1987, classificou os dados faltantes em três categorias principais (Figura 4).
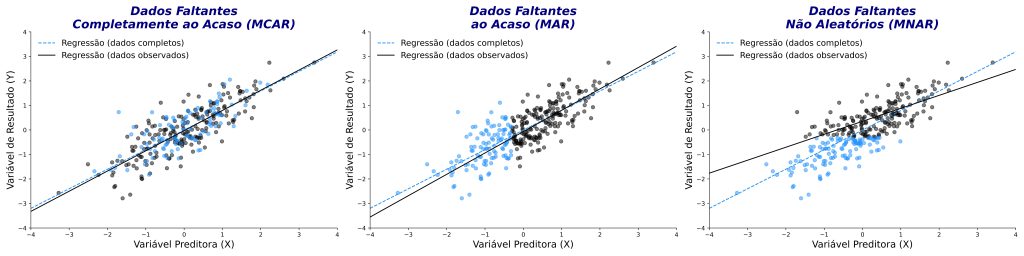
Em seguida, explicamos cada uma delas com exemplos para facilitar a compreensão. Embora a terminologia por ele introduzida seja pouco intuitiva, ela se baseia no grau de aleatoriedade das perdas, com base no papel da variável no modelo estatístico — quer como variável preditora (X) ou como variável de resultado (Y).
Dados faltantes completamente ao acaso (MCAR)
Os dados faltantes completamente ao acaso (missing completely at random, MCAR) ocorrem quando a ausência das informações não tem relação com qualquer variável do estudo, observada ou não observada (Figura 5).
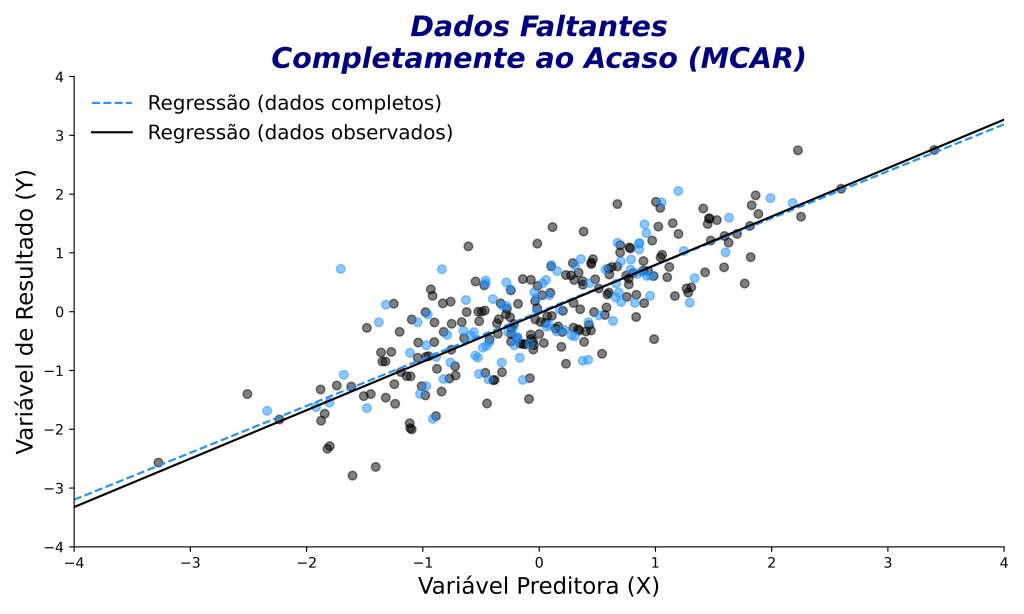
Por exemplo, um participante esquece de responder a uma pergunta qualquer sobre sua rotina semanal. Essa ausência não está relacionada à idade, escolaridade ou qualquer outro fator.
Nesse caso, a exclusão dos dados tende a não enviesar os resultados (Figura 5), pois os dados ausentes são, de fato, aleatórios. No entanto, se a quantidade de dados ausentes for grande, isso acarretará em perda de poder estatístico.
Dados faltantes ao acaso (MAR)
Os dados faltantes ao acaso (missing at random, MAR) ocorrem quando a ausência está relacionada a variáveis observadas, mas não ao valor faltante em si (Figura 6). Em outras palavras, o valor ausente é independente da variável de resultado, mas não da variável preditora.
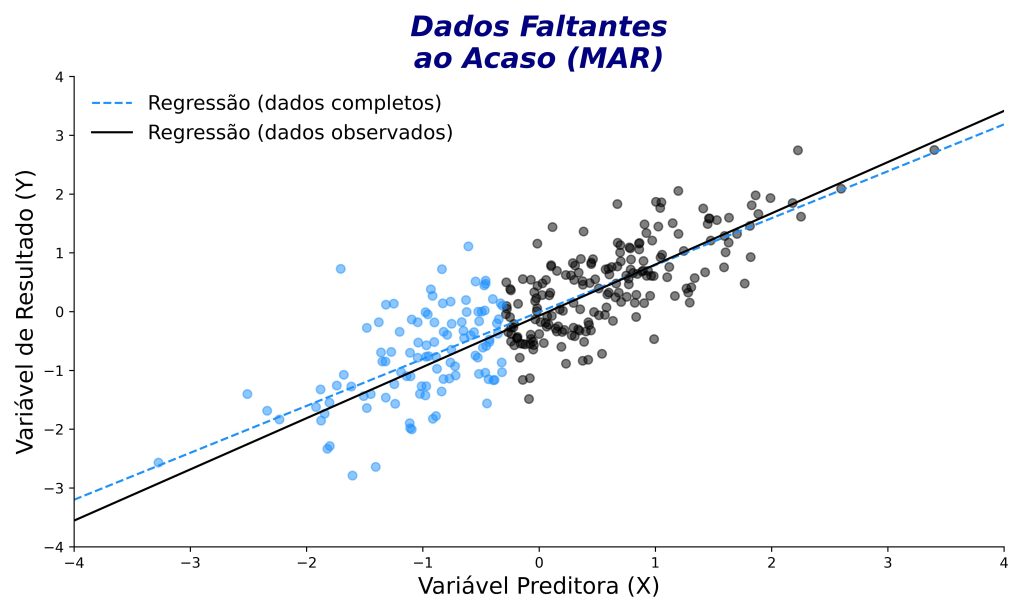
Por exemplo, em uma pesquisa com a população geral, participantes mais velhos podem não responder à pergunta “qual era o padrão de compras dos seus pais?”, justamente por não se lembrarem dessa informação. Desse modo, a ausência está ligada à idade (uma possível variável preditora), não à resposta ao item em si (uma possível variável de resultado).
Embora menos ideal que o MCAR, é possível trabalhar com dados MAR usando técnicas apropriadas de imputação. Contudo, a mesma ressalva sobre poder estatístico também vale para dados MAR.
Dados faltantes não aleatórios (MNAR)
Os dados faltantes não aleatórios (missing not at random, MNAR) surgem quando a probabilidade de ausência está diretamente relacionada ao próprio valor que falta (Figura 7). Em outras palavras, o valor ausente depende da própria variável de resultado cujo valor está ausente.
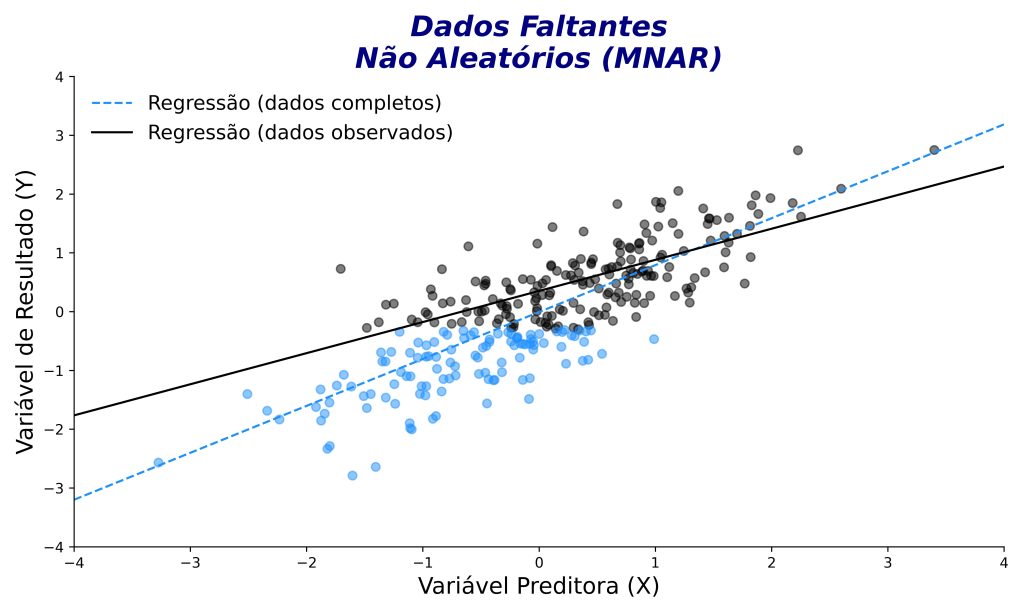
Por exemplo, em uma pesquisa sobre autoestima, alguns participantes podem evitar responder perguntas sobre imagem corporal. Se a recusa ocorrer justamente porque essas pessoas se sentem desconfortáveis com o próprio corpo, teremos um caso de dados MNAR — ou seja, o que está faltando está diretamente ligado ao motivo da ausência de resposta.
Dos três tipos de dados ausentes, esse é o caso mais delicado. A própria ausência carrega significado psicológico ou teórico e, portanto, pode distorcer os resultados se ignorada.
Saiba mais: Dados faltantes (missing): O que são e quais os tipos?
Quais são as consequências de se ignorar dados faltantes?
Historicamente, era comum excluir participantes com qualquer valor ausente, em um processo chamado listwise deletion. No entanto, essa abordagem tem sérios problemas:
- Redução do tamanho amostral, o que diminui o poder estatístico dos testes.
- Aumento da margem de erro e do intervalo de confiança.
- Dificuldade de comparação entre análises que usam subconjuntos diferentes da amostra.
Por exemplo, imagine que nossa amostra de 500 participantes responderam a 20 itens. No entanto, o número de respondentes por item variou de 387 a 432, com apenas 127 respondentes tendo preenchido todos os itens da pesquisa. Se considerarmos apenas os participantes com dados completos (listwise deletion), nossa amostra final consistirá em apenas 31,75% da amostra inicial.
Além disso, se os dados não forem MCAR, essa exclusão pode introduzir vieses e comprometer a generalizabilidade dos resultados.
Como lidar com dados faltantes?
Nos últimos anos, os pesquisadores passaram a usar técnicas mais sofisticadas para tratar valores ausentes, evitando a simples exclusão de casos.
Uma das primeiras soluções foi a imputação por valor médio, onde substituímos o valor ausente pela média daquela variável. No entanto, essa técnica reduz artificialmente a variabilidade dos dados, afetando o desvio-padrão e comprimindo correlação da variável com medidas externas. Por isso, não recomendamos sua utilização.
Em seguida, apresentamos duas técnicas mais adequadas para lidar com dados faltantes.
Maximização da expectativa
A técnica de maximização da expectativa (expected maximization, EM) consiste em estimar os valores ausentes com base na média e na covariância das variáveis observadas. O processo se repete diversas vezes até que os resultados se estabilizem e não apresentem mais diferenças estatisticamente significativas entre as iterações.
Embora eficaz, essa técnica depende de pressupostos fortes sobre a distribuição dos dados, e nem sempre é a melhor escolha.
Imputação múltipla
A técnica da imputação múltipla (multiple imputation) é considerada o padrão-ouro no tratamento de dados faltantes. Ela cria múltiplos bancos de dados completos, nos quais os valores ausentes são preenchidos com estimativas plausíveis.
A partir desses conjuntos, o pesquisador calcula médias, desvios e intervalos de confiança considerando a variabilidade entre as imputações. Isso oferece maior precisão e menor viés, principalmente quando os dados são MAR.
Veja também: Análise de dados faltantes (missing) no SPSS – Definições e melhores práticas
Conclusão
Esperamos que o conteúdo tenha ficado claro e que você tenha compreendido a importância de se atentar para a natureza dos dados faltantes em suas próprias pesquisas.
Se você precisa aprender análise de dados, então faça parte da Psicometria Online Academy, a maior formação de pesquisadores quantitativos da América Latina. Conheça toda nossa estrutura aqui e nunca mais passe trabalho sozinho(a).
Referências
Austin, P. C., White, I. R., Lee, D. S., & van Buuren, S. (2021). Missing data in clinical research: A tutorial on multiple imputation. Canadian Journal of Cardiology, 37, 1322–1331. https://doi.org/10.1016/j.cjca.2020.11.010
Ellenberg, J. (2015). O poder do pensamento matemático: A ciência de como não estar errado. Zahar.
Hair, J. F., Jr., Black, W. C., Babin, B. J., Anderson, R. E., & Tatham, R. L. (2009). Análise multivariada de dados (6ª ed.). Artmed.
Rubin, D. B. (1987). Multiple imputation for nonresponse in surveys. John Wiley & Sons.
Como citar este post
Lima, M. (2025, 5 de maio). O que são dados faltantes? Blog Psicometria Online. https://www.blog.psicometriaonline.com.br/o-que-sao-dados-faltantes/